
Introduction
Hello, this is Pike8. Do you use templates or snippets in competition programming? I mainly use VSCode snippets. This time, I would like to introduce some snippets that I has updated after participating in several competitions.
Template vs. Snippet
When I started the competitive programming, I was torn between using a template or a snippet. A template here means that you prepare a file in advance with frequently used macros, constants, functions, etc. as shown below, and copy and use them when solving problems.
#include <bits/stdc++.h>
using namespace std;
// clang-format off
struct Fast {Fast() {std::cin.tie(0); ios::sync_with_stdio(false);}} fast;
// clang-format on
#define REP(i, n) for (int i = 0; i < (int)(n); i++)
// Add more macro, constants or function here
int main() {
}On the other hand, a snippet in VSCode is availabvle by adding JSON as follows to .vscode/[any string].code-snippets and then use the editor’s completion function to complete the code. If you use IntelliJ or CLion, you can use a similar feature called Live Template.
{
"main": {
"body": [
"#include <bits/stdc++.h>",
"using namespace std;",
"",
"// clang-format off",
"struct Fast {Fast() {std::cin.tie(0); ios::sync_with_stdio(false);}} fast;",
"// clang-format on",
"#define int long long",
"",
"int main() {",
" $0",
"}",
""
],
"prefix": "main"
},
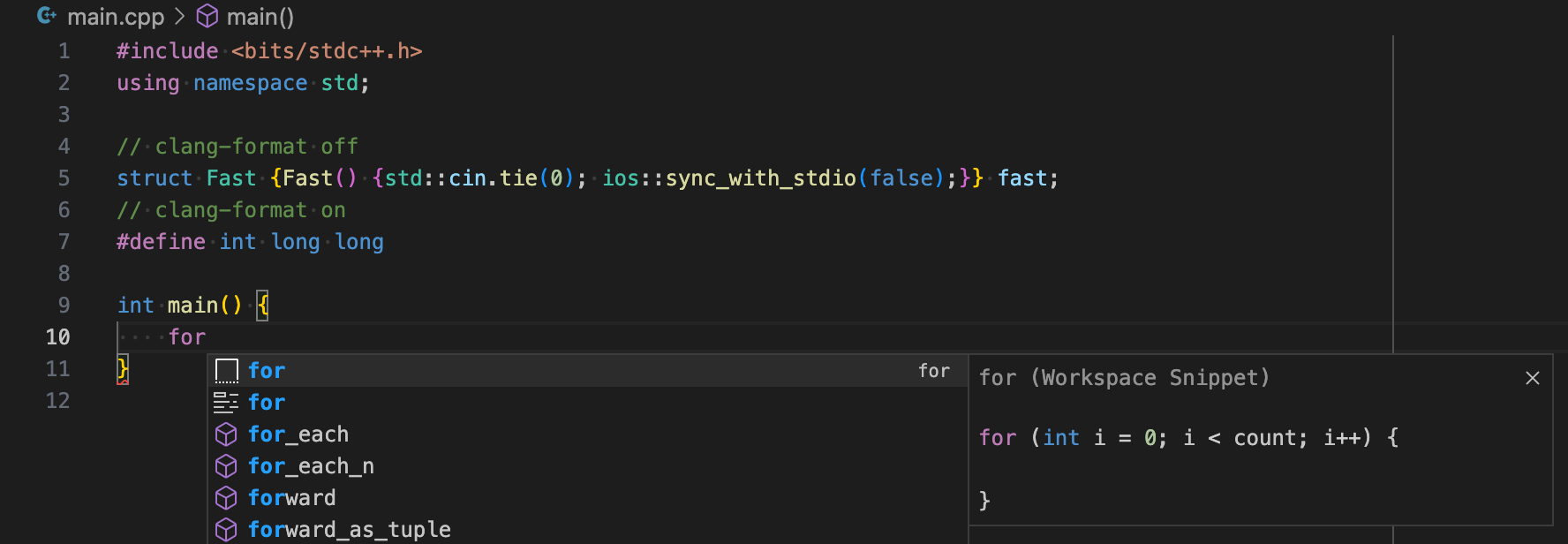
"for": {
"body": [
"for (int ${1:i} = ${2:0}; $1 < ${3:count}; $1++) {",
" $0",
"}"
],
"prefix": "for"
},
// Add more snippets here
}
One advantage of using templates is that they can be used in any environment. This is useful for contests where personal computers and editors are not available. On the other hand, the advantage of using snippets is that you can omit unused code from the file and thus add new snippets quite easily. I currently use snippets rather than templates, since it participates mainly in AtCoder and does not see much advantage in the former.
Snippet
Here is the .code-snippets file that I use for AtCoder. Below are the snippets defined in this file.
Words in the code that are written in all capitals are sequentially focused by the cursor when completed by the snippet and can be easily changed.
main function
// "main"
#include <bits/stdc++.h>
using namespace std;
// clang-format off
struct Fast {Fast() {std::cin.tie(0); ios::sync_with_stdio(false);}} fast;
// clang-format on
#define int long long
signed main() {
}Completes the main function and the include statement that is added each time, etc. Also, I treat int as long long. There are pros and cons to this, and I have long avoided using it, but now it has been adopted to avoid WA due to int overflow that occur when I forget it. However, even in this case, you must be careful not to use atoi where atoll should be used, or pass 0 for the initial value of accumulate where 0LL should be passed, as these will cause an overflow.
Input
// "ci"
TYPE IN;
cin >> IN;
// "ci2" ~ "ci5"
TYPE IN1, IN2;
cin >> IN1 >> IN2;
// "civec"
vector<TYPE> VEC(SIZE);
for (auto &&in : VEC) {
cin >> in;
}
// "civec2"
vector<vector<TYPE>> VEC(SIZE1, vector<TYPE>(SIZE2));
for (auto &&row : VEC) {
for (auto &&in : row) {
cin >> in;
}
}civec and civec2 are used to read standard input into a vector.
Output
// "co"
cout << OUT << '\n';
// "co2" ~ "co5"
cout << OUT1 << OUT2 << '\n';
// "covec"
for (auto out = VEC.begin(); out != VEC.end(); out++) {
cout << *OUT << (out != --VEC.end() ? ' ' : '\n');
}
// "covec2"
for (auto &&row : VEC) {
for (auto out = row.begin(); out != row.end(); out++) {
cout << *OUT << (out != --row.end() ? ' ' : '\n');
}
}
// "coyesno"
cout << (CONDITION ? "Yes" : "No") << '\n';
// "coaccuracy"
cout << fixed << setprecision(12);
// "cobool"
cout << boolalpha;
// "copad"
cout << setfill('0') << setw(LENGTH) << OUT << '\n';covec and covec2 are used to write out vectors. coyesno outputs Yes or No depending on the condition. You can choose the format of the actual character output during completion.

Type
// "ll"
long long
// "vec"
vector<TYPE>
// "vec2", "vec3"
vector<vector<TYPE>>
// "set", "umap"
set<TYPE>
// "uset", "umap"
unordered_set<TYPE>
// "usetcustom", "umapcustom"
unordered_set<TYPE, TYPE::Hash>
// "pq"
priority_queue<TYPE>
// "pqreverse"
priority_queue<TYPE, vector<TYPE>, greater<TYPE>>Completes long type names such as multidimensional vector or unordered_set. usetcustom and umapcustom are used to make your own structures into elements of unordered_set or unordered_map. Structures that define Hash, or etc can be complemented with this snippet.
Variable declaration
// "vecsized"
vector<TYPE> NAME(SIZE);
// "vec2sized", "vec3sized"
vector<vector<TYPE>> NAME(SIZE1, vector<TYPE>(SIZE2));
// "pqlambda"
priority_queue<TYPE, vector<TYPE>, function<bool(TYPE, TYPE)>> NAME([&](TYPE VALUE1, TYPE VALUE2) { });vecsized is the declaration of a vector with a specified size. It is useful to be able to enter the TYPEs of multidimensional vector at once, since the TYPE specifications overlap. pqlambda is used to specify a non-comparable structure as a TYPE and to specify the comparison method in a lambda.
Struct
// "struct2", "struct3"
template <class Type> inline void hash_combine(size_t &h, const Type &value) noexcept {
size_t k = hash<Type>{}(value);
uint64_t m = 0xc6a4a7935bd1e995;
int r = 47;
k *= m;
k ^= k >> r;
k *= m;
h ^= k;
h *= m;
h += 0xe6546b64;
}
struct NAME {
TYPE1 VALUE1;
TYPE2 VALUE2;
string to_string() const {
ostringstream oss;
oss << "NAME(VALUE1=" << VALUE1 << ", VALUE2=" << VALUE2 << ")";
return oss.str();
}
bool operator==(const NAME &other) const {
return tie(VALUE1, VALUE2) == tie(other.VALUE1, other.VALUE2);
}
bool operator<(const NAME &other) const {
return make_pair(VALUE1, VALUE2) < make_pair(other.VALUE1, other.VALUE2);
}
struct Hash {
size_t operator()(const NAME &p) const noexcept {
size_t seed = 0;
hash_combine(seed, p.VALUE1);
hash_combine(seed, p.VALUE2);
return seed;
}
};
};This is a snippet for a structure with two or three elements, overloading operator< for use in set and map. I define a Hash structure for use with unordered_set and unordered_map, and since pairs and tuples are prone to element access errors, I use this snippet to define the structure as much as possible.
Constant
// "infi"
const int INF = 1e9;
// "infll"
const long long INF = 1e18;
// "dxdy"
const vector<int> DX = {1, 0, -1, 0};
const vector<int> DY = {0, 1, 0, -1};
// "drowdcol"
const vector<int> DROW = {1, 0, -1, 0};
const vector<int> DCOL = {0, 1, 0, -1};dxdy and drowdcol are used to scan the coordinate plane and the front/back/left/right of a two-dimensional vector.
Loop
// "for"
for (int I = 0; I < COUNT; I++) {
}
// "forreverse"
for (int I = COUNT - 1; I >= 0; I--) {
}
// "forrange"
for (auto &&ELEMENT : VEC) {
}This is a snippet for writing normal for statements, decrementing for statements, and range-based for statements.
Frequent code
// "lf"
'\n'
// "lforspace"
(CONDITION ? ' ' : '\n')
// "all", "allreverse"
VEC.begin(), VEC.end()
// "chmax", "chmin"
MAX = max(MAX, TARGET);
// "rangeexclusive", "rangeinclusive"
MIN <= VALUE && VALUE < MAXlforspace is sometimes used to output a vector; all and allreverse are used to pass a vector as an argument, such as sort and accumulate. chmax and chmin are used to update the current value only if the result is greater than or less than the current value. rangeexclusive and rangeinclusive are used to check whether an index is within the range of an array, for example, when traversing a two-dimensional array.
Error-prone code
// "popcount"
__builtin_popcount(VALUE)__builtin_popcount returns the number of bits that are 1. A function named __popcount is defined in the bit header file with a similar name. Once I used __popcount without including bit and got a WA, I have been using this snippet ever since.
Function and Lambda
// "fun"
function<RET(TYPE)> NAME = [&](TYPE VALUE) {
};
// "fun2"
function<RET(TYPE1, TYPE2)> NAME = [&](TYPE1 VALUE1, TYPE2 VALUE2) {
};
// "lambda"
[&](AUTO const &VALUE) { }
// "lambda2"
[&](AUTO1 const &VALUE1, AUTO2 const &VALUE2) { }fun and fun2 are used when you want to define a local function in a function. This is useful when defining recursive functions such as DFS. lambda and lambda2 are used when you want to pass a function to sort, accumulate, or etc. Since all of them specify & in the closure, you can access variables in any scope. If you are writing code in a competitive programming, you should have no problem without worrying about scope.
Collection Operation
// "filter"
vector<TYPE> FILTERED;
copy_if(VEC.begin(), VEC.end(), back_inserter(FILTERED), [&](TYPE const &value) { });
// "transform"
vector<TYPE> TRANSFORMED;
transform(VEC.begin(), VEC.end(), back_inserter(TRANSFORMED), [&](AUTO const &value) { });
// "partialsum"
vector<TYPE> SUMS = {0};
partial_sum(VEC.begin(), VEC.end(), back_insert_iterator(SUMS));These are operations on collections that are often used. transform is a so-called mapping operation. partialsum is used to find the cumulative sum.
Algorithm
Binary search
// "binarysearch"
auto isOk = [&](TYPE mid) {
};
TYPE ok = OKBOUND;
TYPE ng = NGBOUND;
while (abs(ok - ng) > 1) {
type mid = (ok + ng) / 2;
if (isOk(mid)) {
ok = mid;
} else {
ng = mid;
}
}Complements the binary search algorithm.
String conversion
// itos
string itos(long long value, int radix) {
if (value == 0) {
return "0";
}
string res;
bool isNegative = value < 0;
value = abs(value);
while (value > 0) {
int r = value % radix;
char c = r <= 9 ? r + '0' : r - 10 + 'a';
res = c + res;
value /= radix;
}
if (isNegative) {
res = '-' + res;
}
return res;
}Completes a function that converts a number to a string. Since std::to_string does not allow specifying a radix, this is used when a radix is required.
Iterative square method
// "powll"
long long powll(long long base, long long exponent) {
long long ret = 1;
long long remain = exponent;
while (remain > 0) {
if (remain % 2 == 1) {
ret *= base;
}
base *= base;
remain /= 2;
}
return ret;
}Completes a function to computes powers by the Iterative square method. In competitive programming, the remainder of a power divided by a certain number is often obtained, but this function does not perform remainders. To find the remainder, I use pow function in Modint in AtCoder.
Prime Number
// "prime"
bool is_prime(long long n) {
if (n == 1) {
return false;
}
for (long long i = 2; i * i <= n; i++) {
if (n % i == 0) {
return false;
}
}
return true;
}
// "primefact"
vector<long long> get_prime_factorization(long long n) {
vector<long long> ret;
long long remain = n;
for (long long i = 2; i * i <= remain; i++) {
while (remain % i == 0) {
ret.push_back(i);
remain /= i;
}
}
if (remain != 1) {
ret.push_back(remain);
}
return ret;
}prime completes a function to determine prime numbers. primefact completes a function to perform prime factorization.
Permutation and Combination
// "permutation"
void foreach_permutation(vector<TYPE> list, function<void(vector<TYPE>)> callback) {
vector<TYPE> permutation(list.size());
vector<int> indexes(list.size());
iota(indexes.begin(), indexes.end(), 0);
do {
for (int i = 0; i < indexes.size(); i++) {
permutation[i] = list[indexes[i]];
}
callback(permutation);
} while (next_permutation(indexes.begin(), indexes.end()));
}
// "permutation2"
void foreach_permutation(vector<TYPE> list, int count, function<void(vector<TYPE>)> callback) {
vector<TYPE> permutation(count);
vector<TYPE> combination(count);
vector<int> indexes(count);
iota(indexes.begin(), indexes.end(), 0);
function<void(int, int)> dfs = [&](int position, int index) {
if (position == count) {
do {
for (int i = 0; i < indexes.size(); i++) {
permutation[i] = combination[indexes[i]];
}
callback(permutation);
} while (next_permutation(indexes.begin(), indexes.end()));
return;
}
for (int i = index; i < list.size(); i++) {
combination[position] = list[i];
dfs(position + 1, i + 1);
}
};
dfs(0, 0);
}
// "combination"
void foreach_combination(vector<type> list, int count, function<void(vector<type>)> callback) {
vector<type> combination(count);
function<void(int, int)> dfs = [&](int position, int index) {
if (position == count) {
callback(combination);
return;
}
for (int i = index; i < list.size(); i++) {
combination[position] = list[i];
dfs(position + 1, i + 1);
}
};
dfs(0, 0);
}permutation completes a function which receives a lambda function as a parameter for a permutation. permutation2 additionally allows the number of elements to be taken out to be specified. combination completes a function which receives a lambda function as a parameter for a combination of count. They are \(_nP_n\), \(_nP_k\), and \(_nC_k \), respectively.
AtCoder Library
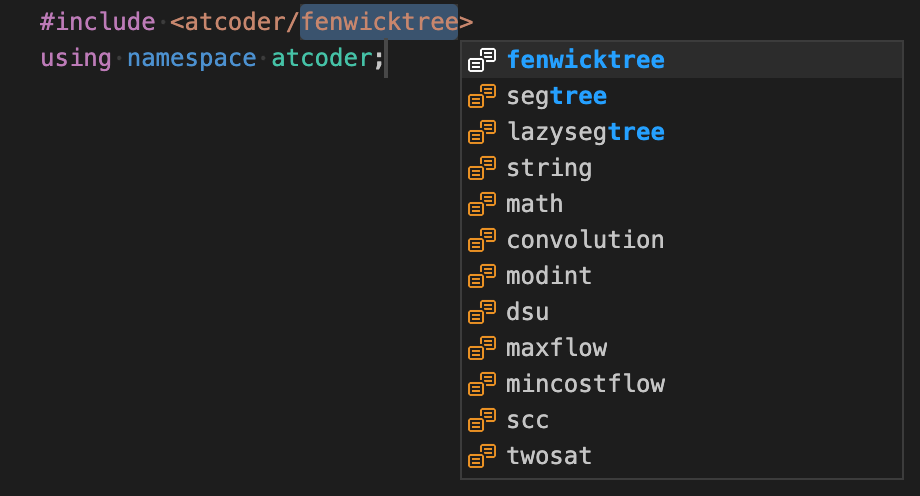
// "acl"
#include <atcoder/FENWICKTREE>
using namespace atcoder;
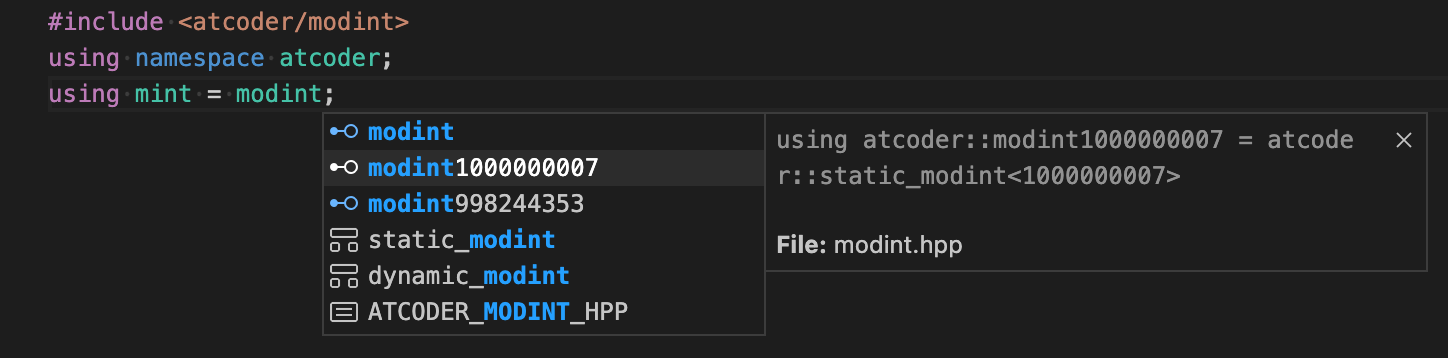
// "mint"
using mint = modint;Here is a snippet for the AtCoder Library. acl is used to include headers. since including atcoder/all might affect the compile time, I make it to choose which headers to include at completion time.
mint is used to define aliases of atcoder::modint1000000007 and atcoder::modint998244353 in modint since they are long.
Impression
In summary, it was quite a lot of snippets. C++ is often more verbose than other languages in terms of code such as operations on collections, but I would like to use templates and snippets to shorten the coding time. And I would like to keep updating .code-snippets for more convenience.
